概述
RouterOS v7支持在多个进程之间拆分任务。 有一个 主 任务,它可以启动/停止子任务,并在这些子任务之间处理数据。每个子任务都可以分配“私有”内存(只有这个特定的任务可以访问)和“共享”内存(所有路由任务都可以访问)。
可以拆分的任务列表:
打印命令的处理;
整个OSPF协议处理;
整个RIP协议处理;
静态配置处理;
路由策略配置;
BGP连接和配置处理;
BGP接收(每个对等体一个任务或按特定参数分组);
BGP发送(每个对等体一个任务或按特定参数分组);
FIB更新。
BGP子任务
BGP的接收和发送可以通过特定的参数分割成子任务,例如,可以按每个对等体运行输入,或者将所有对等体的输入分组并在主进程中运行。在 /routing/bgp/template 中用 input.affinity 和 output.affinity 参数配置来控制这种子任务的分割。在内核较少的设备上通过affinity值可以提高性能,因为在任务之间共享数据要比在一个任务中处理相同的数据慢一些。例如,在单核或双核设备上,在主进程或实例进程中运行输入和输出将提高性能。
BGP最多可以有100个唯一的进程。
所有当前使用的任务及其分配的私有/共享内存都可以用命令来监控:
/routing/stats/process/print
示例输出:
[admin@BGP_MUM] /routing/stats/process> print interval=1
Columns: TASKS, PRIVATE-MEM-BLOCKS, SHARED-MEM-BLOCKS, PSS, RSS, VMS, RETIRED, ID, PID, RPID, PROCESS-TIME, KERNEL-TIME, CUR-BUSY, MAX-BUSY, CUR-CALC, MAX-CALC
# TASKS PRIVATE-M SHARED-M PSS RSS VMS R ID PID R PROCESS- KERNEL-TI CUR- MAX-BUSY CUR- MAX-CALC
0 routing tables 11.8MiB 20.0MiB 19.8MiB 42.2MiB 51.4MiB 7 main 195 0 15s470ms 2s50ms 20ms 1s460ms 20ms 35s120ms
rib
connected networks
1 fib 2816.0KiB 0 8.1MiB 27.4MiB 51.4MiB fib 255 1 5s730ms 7m4s790ms 23s350ms 23s350ms
2 ospf 512.0KiB 0 3151.0KiB 14.6MiB 51.4MiB ospf 260 1 20ms 100ms 20ms 20ms
connected networks
3 fantasy 256.0KiB 0 1898.0KiB 5.8MiB 51.4MiB fantasy 261 1 40ms 60ms 20ms 20ms
4 configuration and reporting 4096.0KiB 512.0KiB 9.2MiB 28.4MiB 51.4MiB static 262 1 3s210ms 40ms 220ms 220ms
5 rip 512.0KiB 0 3151.0KiB 14.6MiB 51.4MiB rip 259 1 50ms 90ms 20ms 20ms
connected networks
6 routing policy configuration 768.0KiB 768.0KiB 2250.0KiB 6.2MiB 51.4MiB policy 256 1 70ms 50ms 20ms 20ms
7 BGP service 768.0KiB 0 3359.0KiB 14.9MiB 51.4MiB bgp 257 1 4s260ms 8s50ms 30ms 30ms
connected networks
8 BFD service 512.0KiB 0 3151.0KiB 14.6MiB 51.4MiB 12 258 1 80ms 40ms 20ms 20ms
connected networks
9 BGP Input 10.155.101.232 8.2MiB 6.8MiB 17.0MiB 39.1MiB 51.4MiB 20 270 1 24s880ms 3s60ms 18s550ms 18s550ms
BGP Output 10.155.101.232
10 Global memory 256.0KiB global 0 0
路由表更新机制
下图试图以更友好的方式解释路由表更新机制是如何工作的。
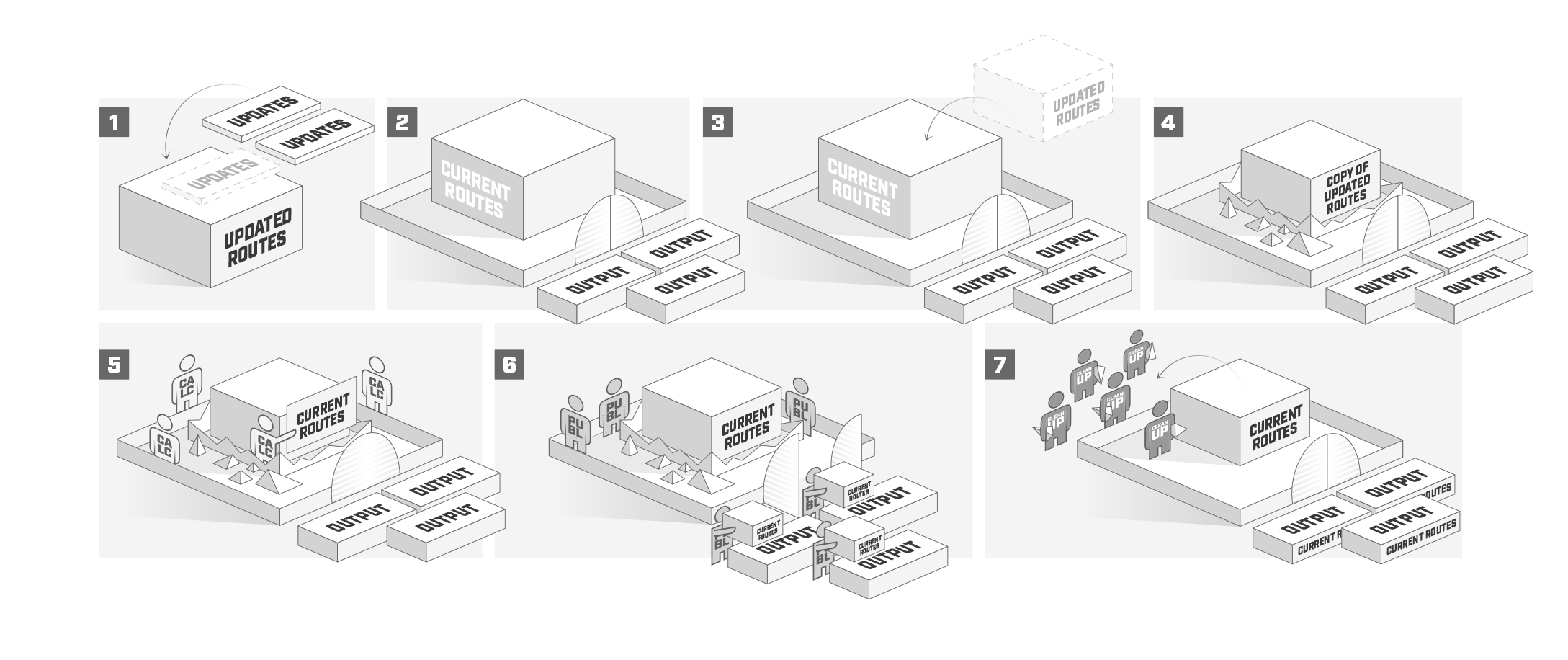
路由协议通过以下步骤不断循环:
main 进程等待其他子任务的更新(1);
main 开始计算新的路由(2..4),如果:
从子任务接收更新;
协议没有公布所有路由;
配置发生变化或链路状态发生变化;
在计算新路线时(5)发生以下事件:
所有收到的更新都应用到路由上;
正在确定网关的可达性;
递归路由正在解析;
publish 事件在 current 路由被发布时被调用。在此阶段,当前的路由不会改变,但协议仍然可以接收和发送更新(6)。
清理和释放未使用的内存(7)。在这一步中,所有不再在新 current 表中使用的东西都被删除(路由,属性等)。
考虑 updated 和 current 作为路由表的两个副本,其中 current 表(2)是当前使用的表,updated (1)是将在下一个发布事件(3和4)中发布的候选路由表。这种方法可以防止协议在 main 进程执行 publish 时用缓冲的更新填充内存,相反,协议将最新的更新直接发送到 main 进程,然后将新的更新复制到 updated 表中。稍微复杂一点的是OSPF,它内部有类似的过程来选择当前的OSPF路由,然后发送到 main 进行进一步的处理。